12 minutes
A Christmas (Card) Story
TLDR; This year, I created a Christmas card using generative AI techniques. I learned a lot about the power and limitations of the technology, the bias’s of models, the new industries popping up around AI/ML, and people’s sometimes surprising reactions to the end result.
Every year, I make a Christmas card, almost always featuring myself and my wife doing something silly. For example, here is 2022’s effort.

This was produced by my standard workflow of making separate photo’s of Margie and me against a chroma key background, and then using the Gimp (open source alternative to Photoshop) for compositing up the image. (Full disclosure, I did actually generate the background with an AI)
This year, I decided to use the Christmas card as an excuse to take a proper dive into generative AI.
The brief to myself, was as always, Margie and me, and a situation that could be taken in at a glance. I also had the negative brief of the output not looking obviously AI generated. So I decided to go for something pretty traditionally Christmassy.
My initial trials were not promising. Although the standard online generators like Midjourney, Dreamstudio and the rest will churn out endless airbrushed warriors, insouciant avocados, or astronauts on horseback, starting with real people as characters and creating scenes, while maintaining good likenesses proved from difficult to near impossible.
Basically, image to image generation, as it’s called, doesn’t have enough context to know what are the important features that need to be retained from character source image. So, starting with this image of me.
 and the following prompt to Dreamstudio in image to image mode
and the following prompt to Dreamstudio in image to image mode
‘A victorian postcard of a christmas elf, watercolor, christmas tree in background’
with a default image strength of 35% got this:

Somewhat elf’ish, but not very much like me. Turning up the percentage of my image that was in the result gave me this:

More like me, but the rest of the source image is leaking through, as the AI doesn’t know which bits of the image are fundamentally me, and which are extraneous detail, like the background, my sweatshirt, or my pose. Now this is a pretty crude example, but I spent considerable time tweaking the process without getting much better results.
So, the naive approach having proved impractical, I started to look into the process of ‘fine tuning’ AI models. This consists of modifying standard models so that they have a deeper understanding of a particular target style or subject.
[Digression: It’s very difficult not to anthropomorphize when talking about AI’s, and use words like ‘understand’, ‘grasp’ or ’think’. However, as you’ll perhaps see as we progress, as I got deeper into the subject it increasingly felt more like wrestling with an idiot than talking to an intelligence ]
By this stage, I’d made the decision to use Stable Diffusion as my image generator, as it seemed to be the most open system to work with. DALLE-E and Midjourney were the other candidates, but it seemed that fine tuning was most accessible with Stable Diffusion, so the rest of this article will be about that.
Fine tuning is one of the fastest evolving subjects in generative AI. I learned there are currently four methods of fine tuning Stable Diffusion, all of which have been created in the last year or so.
- Dreambooth
- Textual Inversion
- LoRA
- Hypernetworks
There followed a few days of watching comparison videos of these techniques.
[More digression: the cottage industry that makes tutorials about image generation seems to mostly monetise by making YouTube videos rather than blog posts or web page, thus I landed up watching a lot of ads]
To keep the story short, Hypernetworks were outmoded, even though less than two years old, Dreambooth created very large, new models, Textual Inversion was OK, if tricky, but LoRA came out as the new hotness.
LoRA stands for Low Rank Adaptation, and basically consists of inserting extra, small, layers into the Stable Diffusion model. These are trained up on a set of example images of the person, concept or thing that you wish to be able to accurately generate. The LoRA is then associated with a magic keyword that tells Stable Diffusion to insert the person/concept in the output image. So, I my case, I was aiming for something like
‘picture of mkarliner as a Christmas Elf’.
OK, so we have an approach, what’s the hardware and software I need to do this?
I had a few alternatives. I could fire up a virtual machine with a GPU on Amazon AWS or Google Cloud, build my own machine with a good enough GPU to be able to handle the load, or look at one of the new sites that provide pay-as-you-go compute facilities targeted on AI, like vast.ai or runpod.io.
In the end, I landed up using runpod. Runpod provide ready made templates for complete machines (actually containers) that host a full set of AI tools for various different jobs, and offer large number of differently powered systems to run them on, charged by the hour. You put some money in the slot, push the button and the template builds you a custom machine in a few minutes.
For most of the time I was working on this I opted for a machine equipped with an NVidia RTX 3090 and 24GB of VRAM. As the NVidia board is currently selling on ebay for around £750 second hand, the hourly charge of 44¢ / hour seemed pretty much a bargain. This machine was way down on the low end of what was on offer, but I reasoned that while I was learning, I’d waste a lot of time and make a lot of mistakes, and it was better to do it on a cheaper system than an expensive one.
More research, more watching videos. It turns out that the most popular UI for Stable Diffusion is call Automatic1111, and the most popular LoRa training tool is Kohya_SS. Both of these presented pretty intimidating user interfaces, there are a lot of options to play with!
The first step was to prepare a set of reference images of myself and Margie to train the Lora on. These needed to be in as many different combinations of clothing, lighting and backgrounds as possible. As I learned to my cost, if I used source images from just a couple of shoots, the training would tend to include say, my sweatshirt as part of its concept of me. Here’s a collage of part of my training set.
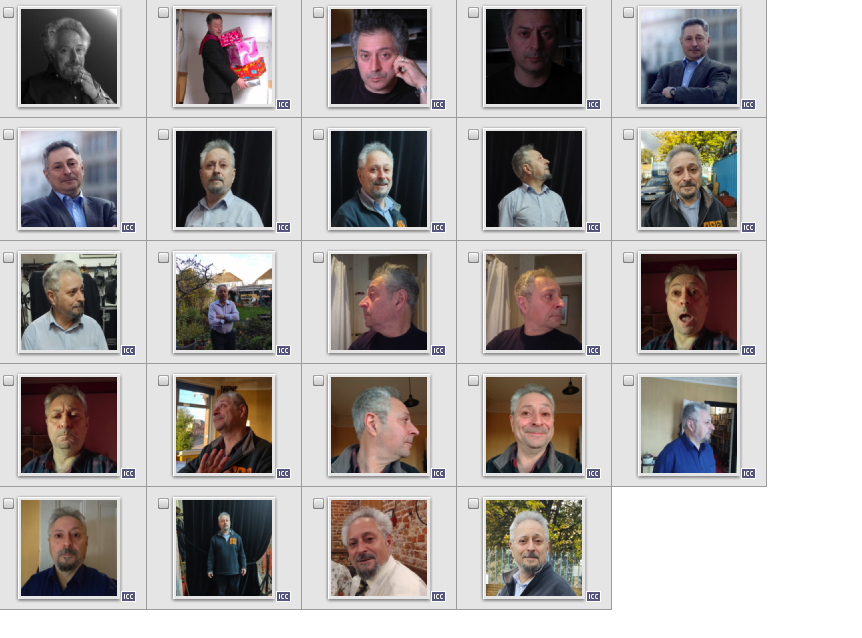
The next step was to create captions for all of these images. This is a crucial part of the process, as it allows the model to eliminate details that are not part of my essence. So, the caption for the image at the top of this post was
’ mkarliner, with a beard, he is wearing grey sweater with orange letters and a blue shirt, he is in front of a trees and railings’.
Note the phrase ‘with a beard’. I’d shaved my beard off between reference shoots, so I could make the beard an optional part of my appearance. Telling the training, ‘with a beard’ made the beard an optional extra.
Next was obtaining set of regularisation images. I was going to train the LoRA on myself as ‘mkarliner’ with a general class of ‘man’. I pulled down around 500 images of ‘man’ from the Internet, which the training would use to run against the specific images of ‘mkarliner man’.
Now we actually got round to doing the training runs. Setting this up was yet another learning experience. To get the best use of the rented machine, the parameters had to be set to use as much of the available memory as possible, but not so much that we ran out of machine resources. My initial efforts were too conservative and the estimates for training times were in the order of 9 or more hours. By reducing the number of training images and adjusting the size of each run of training I got to about 75% utilisation and a training time of about two hours.
The training itself is an evolutionary process, grouped into ’epochs’, each of which ends in generating a model of me. A the end of each epoch the system would create a test image of me so I could monitor its progress.
It’s reasonable to think that the longer you allow the learning process to continue, the better the model will get, but that’s not the case.
Training will reach an optimal point, after which it starts to suffer the bane of machine learning, which is overfitting. Overfitting means that the model will learn too well, and start to become inflexible, and refuse to generate anything except material from the training images. In my case it turned out that epoch 7 of 10 was the one that seemed to give the nicest results, in Margie’s case it was epoch 10 of 20.
Phew. After days of effort and endless articles and YouTube adverts, I’d managed to created two LoRA’s of myself and Margie. Time to start the actual creative work.
It was at this point that I started to come up against the biases built into the generative AI models. After all, the input for these models is a somewhat curated selection of images from the Internet, and associated metadata. The Internet itself is quite skewed, and any act of curation, however well meant, introduces its own take on top. One word prompts are a good way of probing what bias there is. Here is Dreamstudio’s response to the single word ‘woman’.

So, woman is always young, white, and in a fashion shoot.
And here’s ‘genius’

White, male, old.
So there is not such thing as neutral AI system, the language used to prompt the engine tends to reflect the wider prejudices of the Internet as a whole, which meant that trying to get it to express what I wanted to express would be an uphill battle to get results that were not just a partially digested version of existing memes.
Stable Diffusion’s text to image generation is controlled by a bewildering number of parameters, but for sanity’s sake if nothing else, I concentrated on a handful, the prositive prompt, the negative prompt, the seed, and the sampler.
The positive prompt is what most people think of when using text to image AI, it’s a comma separated list of prompt elements. Here’s one for my image:
full length watercolor of mkarliner , smiling slightly, wearing a christmas elf outfit with, christmas tree, post card , victorian, high detail, sharp <lora:mike:0.8>
the <lora> section tells Stable Diffusion to add in my specific model.
the negative prompt lists stuff you don’t want:
Negative prompt: (visible teeth)
[All through the process SD had an annoying habit of putting either putting big cheesy grins on both of us, or making us look rather stern. I think this was an issue with the selection of reference images. Getting acceptable smiles took the most amount of time of any element. Margie landed up with ‘gioconda smile’]
The seed is a pseudo-random number the system generates on each run so you get a different so you get a different variation of the image each time.
Working from my basic prompt, I’d repeatedly generate images until it gave me one that seemed have all the elements I was looking for. Then, I’d tell the system to freeze the seed, and start finessing the prompts and other parameters.

So here, the overall feel and pose is good, and the background works, but I think I look a little too boyish for my taste. By freezing the seed, I could hold most of the image static and just start adjusting details. Adding the ‘beard’ to the final prompt, changed the feel of the character quite a bit, while retaining all the other elements.

Another issue turned out to be limitations of LoRA itself. Once I’d settled on the idea of a Victorian Chistmas card, starring myself as an elf and Margie as a fairy godmother, it didn’t take too long, using the methods above, to get acceptable versions of each of us, although I probably generated several hundred of each before settling on a final output.
However, trying to use both the LoRA’s in the same image proved pretty much impossible. It seems that although I was a sub-class of ‘man’ and Margie a sub-class of ‘woman’, we were both sub-classess of ‘person’. Using both LoRA’s in one prompt resulted in some interesting, if disturbing images that blended both of us together.

I did try some advanced tools that supposedly restricted the effects of a LoRA to a given segment of the image, but I couldn’t get them to work with Stable Diffusion XL, which was the version I was using.
So, in the end, I cheated. I made two separate card images, arranged together on generated old desktop with generated holly, and comp’d the whole thing together with my old pal, Gimp. Here’s the final output.

Coda: The card has been sent out to over a hundred people now, and the responses are interesting.
Overall, the most striking thing is that people take the image at face value, as a photographic image of us, when we are both considerably older than our avatars. Also, it seems that because it doesn’t conform to the glossy uncanniness of most AI generated art, almost no-one spotted its origins.
Annoyingly, those people who have some knowledge of AI technology, once told of how it was made, tended to be somewhat dismissive of the whole exercise, claiming that anyone could do it. I’ve opted not to engage in this dialogue, I think that if you’ve read this far, you will have learned that it still takes considerable effort to get a tightly controlled output from generative AI.
After I’d sent off the final image to the printers, I could indulge myself with experimenting a bit with our new LoRA’s and combining them with other publicly available LoRA’s from civit.ai.
Civit.ai and other sites proved to be very illuminating and somewhat alarming. Almost overnight, a whole industry has sprung up dedicated to creating custom resources for generative AI. Much of the material is perfectly harmless, but it’s also obvious that there is a huge potential for serious abuse, and not just in terms of NSFW. Looking at what I’ve managed from a standing start and fairly minimal resources, it’s not difficult to imagine what a State Actor could do with say, war scenes or incriminating political imagery.
It’s not obvious to me that there is any real path back. Society is just going to have to evolve an even greater sense of suspicion about the provenance of any information.
On a lighter note, browsing through available concept LoRA’s, I found a favorite, one that had been trained on comic book covers from the 50’s and 60’s.
It turns out that Margie really does make a really great sheriff!
